Is there a link between the linear correlation coefficient and conditional probability?
One day, after observing that the correlation between two zero mean variables was 0.3, someone asked whether this meant that if one variable was positive the probability of the other one being positive is 0.3 too.
The short answer is no, but it’s not that straightforward to explain why; is it that that’s not the right figure or that correlation cannot be interpreted in such a way? The questioner had an interesting intuition, after all, if correlation measures linear dependency of random variables, shouldn’t there be some connection to conditional probabilities (i.e., to the probability of one variable matching the other’s variable variation) at some point?
Binary transformation
The first thing to notice is that the way the question is posed the interest is centered on binary outcomes (positive vs negative) while we often measure correlation for continuous variables (as in fact was the case in the aforementioned presentation).
Hence, the first step in bridging the gap between correlation and probability as framed in this case is to make our continuous variables binary. We call and the events in which the original continuous variables and are above their respective thresholds and and we define the indicator (binary) variables and as:
Of course in some cases our variables might be binary to begin with and we can ignore this step.
Correlation and its constituents
Now let’s recall the definition of correlation, which is none other than the covariance (how two variables vary together), normalized by each variable’s variance, so as to have a scale-independent output, always in the [-1, 1] interval.
Since the goal of this investigation is to bridge correlation with probability, in the following lines we are going to express the variance and covariance in terms of the probabilities of and .
Covariance
Let’s leave the variances for a moment and focus on covariance.
Note that the product will be 0 if either variable is 0 and 1 in the intersection , hence its expected value is the probability of the intersection:
For the other expectations we simply have:
which we can now substitute in the original expression:
We can also rearrange the expression of the intersection conditioning on one of the variables, let’s say , which allows us to take out as a common term:
Analogously, we can decompose conditioning on : , where represents the complementary outcome, i.e., .
We replace in the second term in the brackets by so as to make some cancellations:
This will suffice, now let’s get back to variances.
Variance
Variance is nothing but the covariance of a variable with itself:
Since can only take 0 or 1 values, squaring it makes no difference:
Obviously the same applies to any other binary variable like .
Bringing all together
Now we have all the ingredients to get an expression of correlation that is linked to conditional probabilities in the way it was conceived in the starting question. Let’s start by substituting our previous results in the definition of correlation:
A little bit of rearrangement yields a cleaner expression:
So correlation is linked to the difference in the probability of being positive (here we are assuming as in the initial statement of the problem) when is positive versus negative. Notice how negative correlation implies that positive values of are less likely when is positive as expected. The square root is always positive and can be understood as a scaling factor that ensures correlation stays within its expected boundaries.
Easing interpretability
We can make a last simplifying assumption to get rid of the scaling factor which is slightly hindering interpretability. If we place the binarizing thresholds ( and ) in the median (or equivalently the mean, when the variable is symmetric), we will have and hence:
Since, , we can take it a little bit further:
When we are given a correlation and want to convert it to conditional probability we would use the following alternative arrangement:
Since 0.5 is the marginal probability of , the above expression means that knowing the event has happened, increases the probability of by half the correlation between the indicator variables.
We can make a handful of checks to see everything seems right. As expected, when the correlation is 0, we have , as the two variables are independent, so knowing changes nothing. If it’s 1, , as and share the same probability space. Conversely, if it’s -1, .
Answering the initial question
Going back to our initial example (and including the assumptions we’ve made along the way), if after binarizing we got a correlation of, let’s say, 0.2, that would mean that the probability of being positive when is positive is 0.5 + 0.2/2 = 0.6.
Quick comment on the continuous approach
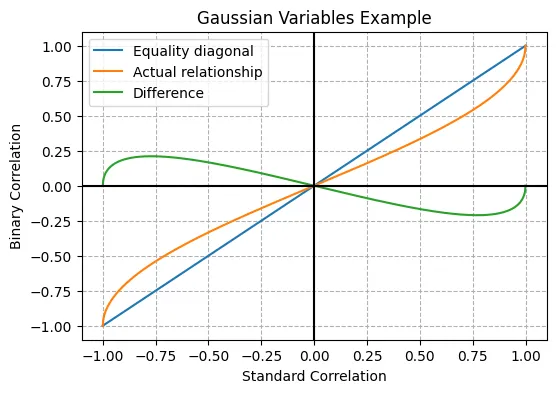
It’s possible to derive directly from a continuous bivariate distribution the conditional probability without recalculating correlation for the indicator variables. This path is however more analytically complex and so it will be left for another time. To get an idea on how results may differ, in the most common case of the normal bivariate distribution, we would have:
Identifying terms with our previous expression we can see that:
As a side note, the value we used in the previous section comes precisely from applying this equation to our original correlation of 0.3. Since , which seems natural. Equality holds at 0 too, and for the values in between the binary correlation is slightly smaller in magnitude (absolute value), reaching a maximum deviation of less than 0.25 at around 0.75, as can be seen in the plot below.